SSH-Grundlagen
Sofern wir Dienste im Netz bereitstellen wollen, brauchen wir in der Regel auch einen sicheren Zugriff auf die entsprechenden Server. Das Protokoll der Wahl dafür ist ssh, das in wenigen Schritten auf einem System installiert ist und sofort seine Arbeit aufnimmt. Die Verbindung zwischen einem Admin-PC/-Notebook und der Remote-Maschine läuft ab diesem Zeitpunkt verschlüsselt.
Es müssen jedoch noch einige weitere Konfigurationen vorgenommen werden, um einen wirklich sicheren Zugriff zu gewährleisten. Im folgenden Beitrag, beschreibe ich die (aus meiner Sicht) dafür notwendigen Schritte, um einen OpenSSH-Server auf einem Linux-System zu betreiben.
SSH steht für Secure Shell und arbeitet nach dem Client-Server-Prinzip. Der Zweck des Protokolls ist, dass sich ein User von einer lokalen Maschine auf einen entfernten Rechner verschlüsselt (secure) und konsolenbasiert (shell) verbinden kann. Nach Verbindungsaufbau können auf der Remote-Maschine entweder Befehle ausgeführt oder Konfigurationen vorgenommen werden.
Auf einem Debian-System kann der Server-Dienst mit dem Befehl …
apt install openssh-server
… installiert werden. Die Konfiguration findet in der Datei /etc/ssh/sshd_config statt. Um sich mit einem SSH-Server zu verbinden, wird ein SSH-Client benötigt, der in der Regel schon auf den unterschiedlichen Betriebssystemen zu Verfügung steht. Seit dem Update 1709 gilt das auch für Windows 10/11-Systeme. Der Weg über manuell installierte Clients (z. B. Putty) ist somit nicht mehr zwingend notwendig.
Bei Verbindungsaufbau, authentfiziert sich …
- der Server bei dem verwendeten SSH-Client mit einem seiner SSH-Host-Keys aus dem Verzeichnis
/etc/ssh/und - der User beim Server via Passwort oder via Public-Key-Authentifizierung.
Bei einer ersten Verbindung von einer lokalen Maschine zu einem Benutzerkonto <username> auf einem SSH-Server <ziel> (kann eine IP-Adresse oder ein DNS-auflösbarer Name sein) via …
ssh <username>@<ziel>
… erfolgt in der Regel eine Warnmeldung, in der ein Fingerprint des verwendeten (öffentlichen) SSH-Host-Keys angezeigt wird. Beispiel:
|
|
Man sollte sich hier grundsätzlich die Zeit nehmen und diese Meldung nicht einfach ignorieren. Die Frage die sich hier stellt ist, ob der Fingerprint aus Zeile 2 (SHA256:a8Uj2qFtWnW2ujoj6A3lZOh6WiqxmfcmqINS/2ttiIE) auch wirklich unseren SSH-Server, mit dem wir uns verbinden wollen, identifiziert.
Bei Installation des SSH-Servers werden die SSH-Host-Keys generiert und die dazugehörigen Fingerprints auf der Konsole ausgegeben. Auszug:
|
|
In diesem Beispiel wurden insgesammt drei verschiedene SSH-Host-Key-Typen erstellt. Wir können sehen, dass der angzeigte Fingerprint vom Typ ED25519 (Zeile 6) unserer oben genannten Warnmeldung entspricht. Daher ist davon auszugehen, dass unser Zielserver tatsächlich das Gerät ist, mit dem wir uns verbinden wollen. In diesem Fall bestätigen wir die Frage oben mit yes. Sind die Fingerprints unterschiedlich, haben wir entweder bei Verbindungsaufbau einen Fehler gemacht oder wir laufen in einen MITM-Angriff (Machine in the Middle).
TippSofern man später nochmal die Fingerprints der SSH-Host-Keys benötigt, können diese mit dem folgenden Befehl ausgegeben werden:for i in /etc/ssh/*pub; do ssh-keygen -lf $i; done
Sobald die Warnmeldung akzeptiert wurde, wird der öffentliche Schlüssel in der Datei ~/.ssh/known_hosts auf dem lokalen Client gespeichert. Dadurch …
- erfolgt keine erneute Warnmeldung bei erneuter Verbindung.
- eine andere Warnmeldung, die nicht einfach ignoriert werden kann, sobald sich der Host-Key ändert.
HinweisFalls wir den Server bei einem Service-Provider bestellen, haben wir keinen Einblick in die SSH-Host-Key-Erzeugung bei der Installation. Je nach Anbieter bekommen wir i. d. R. die Fingerprints der SSH-Host-Keys via Mail oder können sie über ein Portal einsehen.
Nach der Installation des SSH-Servers, nimmt dieser sofort seinen Betrieb auf und lauscht auf TCP-Port 22. Alle lokal angelegten Benutzerinnen und Benutzer, die auf dem SSH-Server existieren, können sich mit Ihrem Passowort anmelden. Ausnahme: Der Benutzer root darf sich i.d.R. nicht mit einem Passwort anmelden.
Der Verbindungsaufbau von einem SSH-Client erfolgt mit dem folgenden Kommando:
ssh -l <username> <ziel>
Häufig verwendet ist auch der folgende Aufruf, der zum gleichen Ergebnis führt:
ssh <username>@<ziel>
Wollen wir nun das Verhalten des SSH-Servers anpassen, müssen wir die notwendige Konfigurationsdatei unter /etc/ssh/sshd_config anpassen.
HinweisBitte beachte das d insshd_config. Es handelt sich dabei um die Konfigurationsdatei für den SSH-Server (d = Daemon). Bei der im selben Verzeichnis befindlichen Dateissh_config, handelt es sich um die Client-Konfiguration.
Die Konfigurationsdatei sshd_config ist übersichtlich aufgebaut. Es gibt zahlreiche Einstellungsparameter, die bereits auskommentiert mit ihrem Default-Wert hinterlegt sind. Ich empfehle an dieser Stelle folgende Anpassung:
- root-Login komplett verbieten:
PermitRootLogin no - SSH-Port auf einen anderen Port im Bereich von 49152 und 65535 (dynamische Ports) legen. Im weiteren Verlauf dieses Artikels verwende ich exemplarisch den Port 54321:
Port 54321 - SSH-Agent-Forwarding abschalten:
AllowAgentForwarding no - Banner-Nachricht vor Authentifizierung hinterlegen:
Banner /etc/issue.net
Die Banner-Mitteilung wird vor der Authentifizierung angezeigt. Um internationaler Rechtsprechung zu genügen, wäre hier ein Text ähnlich dem folgenden Beispiel zu empfehlen, der in der Datei /etc/issue.net hinterlegt wird:
|
|
Änderungen in der /etc/ssh/sshd_config werden erst wirksam, nachdem die Konfiguration neu geladen bzw. der Serverdienst neu gestartet wurde:
systemctl restart sshd.service
Darüber hinaus sollte noch eine Firewall installiert/aktiviert werden. Setzen wir an dieser Stelle auf ufw, brauchen wir zu Beginn nur wenige Befehle:
apt install ufw
ufw allow 54321 comment "Allow SSH from everywhere"
ufw enable
Dass die Firewall korrekt konfiguriert ist, sehen wir mit dem Befehl ufw status verbose:
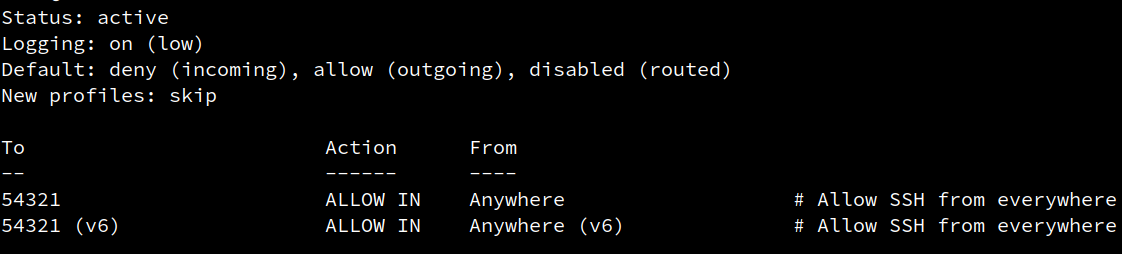
Im weiteren Verlauf, werden wir den Zugriff auf SSH noch weiter einschränken. Für den Anfang kann man auf unserem Server nur den konfigurierten Port für eine SSH-Verbindung verwenden. Möchten wir den Server nach unserer SSH-Konfiguration z. B. als Webserver verwenden, müssen wir für dieses Einsatzszenario noch die TCP-Ports 80 und 443 öffnen.
Im letzten Schritt der Absicherung installieren wir noch fail2ban. Dieses Tool sperrt direkt nach der Installation alle IP-Adressen, die wiederholt Authentifizierungs-Fehler verursachen. Unter Debian 12 installiere ich zusätzlich rsyslog, damit fail2ban gleich problemlos arbeitet.
apt install fail2ban rsyslog
Der Service fail2ban übernimmt sofort seine Arbeit und sperrt alle IP-Adressen für eine definierte Zeit (Default = 1 Stunde) aus, die sich mehr als drei Mal falsch an unserem Server authentifizeren.
Bei Bedarf können wir hier restriktiver konfigurieren oder auch die Login-Versuche für weitere Services überwachen.
Die Verwendung von Passwörtern bei SSH-Verbindungen ist aus folgenden Gründen nicht zu empfehlen:
- Passwörter sind entweder unsicher oder so sicher, dass die wiederholte Eingabe zeitraubend und fehleranfällig ist.
- Jeder Login-Vorgang benötigt immer ein Passwort. Das geht eleganter.
- Wenn auf dem Zielserver mehrere Admins mit Funktions-Accounts arbeiten (z. B. admin), dann muss das Passwort für den SSH-Zugriff im Team geteilt werden. Das führt dazu, dass die Sicherheit weiter aufgegeben wird und dass bei Ausscheiden von Mitarbeitern die Passwörter geändert werden müssen. Das ist nicht praktikabel.
Die Alternative ist, dass statt eines Passworts, jeder user auf dem jeweiligen Arbeitsgerät, ein eigenes SSH-Key-Pärchen für die Authentifizierung erstellt und auf dem SSH-Server die öffentlichen Schlüssel der berechtigen Personen hinterlegt werden.
Für die Erzeugung der Key-Pärchen nutzen wir ssh-keygen auf unserem persönlichen Arbeits-Gerät (PC oder Notebook). Der reine Aufruf des Befehls startet einen Assistenten und erzeugt einen RSA-Key. Wir wollen (sofern vom Server unterstützt) jedoch den etwas moderneren Algorithmus ed25519 verwenden.
Das erreichen wir mit folgendem Kommando:
ssh-keygen -t ed25519
Der Assistent fragt uns nach dem Speicherort und einer Passphrase. Lassen wir den Dateinamen unverändert liegen die beiden erzeugten Dateien (das Keypärchen) unter ~/.ssh/id_ed25519 und ~/.ssh/id_ed25519.pub. Handelt es sich bei meinem Arbeitsgerät um ein Windows-System, sind die beiden Dateien vss. unter C:\Users\<username>\.ssh zu finden.
HinweisBitte an dieser Stelle unbedingt ein solides Passwort bzw. eine Passphrase vergeben.
Der Aufruf der Key-Erzeugung kann noch mit weiteren Optionen erfolgen. Für mich hat sich bewährt, dass ich den Speicherpfad via Option übergebe und das Kommentarfeld anpasse. Der Aufruf sieht dann wie folgt aus:
ssh-keygen -t ed25519 -a 100 -f ~/.ssh/id_ed25519_sshlab -C "<mailadresse>:$(hostname)"
Mit der Option -a 100 wird die Passphrasebestätigung in die länge gezogen. Damit fällt es schwerer das Passwort zu knacken, sollte der Key Mal von meinem Arbeitsgerät gestohlen werden. Mit der Verwendung von -C "<mailadresse>:$(hostname)" wird das übliche Muster <username>@<client-hostname> überschrieben. Das erleichtert im Team die Identifizierung.
TippAus meiner Sicht ist es ratsam, wenn jede Arbeitsstation (z. B. PC und Notebook) ihr eigenes SSH-Key-Pärchen bereit stellt. Wird das Notebook mit einem der beiden SSH-Keys gestohlen, ist es dadurch einfacher, die betroffenen Keys von den SSH-Servern zu löschen und gleichzeitig mit dem PC sorgenfrei weiter zu arbeiten.
Sobald die Keypärchen erstellt wurden, sind nach dem Aufruf oben unter ~/.ssh/ die folgenden beiden Dateien zu finden:

Die Datei mit der Endung .pub enthält den öffentlichen SSH-Schlüssel (1) sowie den Kommentar (2), den wir bei Erzeugung mit der Option -C übergeben haben:

Diese Datei werden wir im weiteren Verlauf auf den oder die SSH-Server schieben. Die zweite Datei beinhaltet den privaten Schlüssel. Diesen hüten wir wie unseren Augapfel und geben ihn niemals raus. Die Dateizugriffsberechtigungen sind hier mit -rw------- entsprechend gesetzt worden.
Der Public-Key muss nun auf den Ziel-Servern in der Datei ~/.ssh/authorized_keys des Users hinterlegt werden, mit dem wir uns auf dem Zielhost verbinden. Das kann mit dem Befehl ssh-copy-id erfolgen:
ssh-copy-id -i ~/.ssh/id_ed25519_sshlab.pub <username>@<IP-Adresse oder FQDN>
Im Anschluss muss man sich via Passwort authentifizieren und der Key wird in die ~/.ssh/authorized_keys von <username>, auf dem SSH-Server eingetragen. Sobald das erledigt ist, kann mit dem Befehl …
ssh -i ~/.ssh/id_ed25519_sshlab <username>@<ziel>
… die Verbindung aufgebaut werden. Es muss bei jedem Verbindungsaufbau die PASSPHRASE des Keys mit übergeben werden.
HinweisHätten wir den Standard-Pfad bei Ausführung vonssh-keygenunverändert gelassen, wäre das Keypärchen unter den Namenid_ed25519undid_ed25519.puberzeugt worden. In diesem Fall brauchen wir bei Verbindungsaufruf die Option-inicht mit angeben. Es reicht dann einssh <username>@<ziel>, da der SSH-Client automatisch diese Default-Schlüssel verwendet.
Im Anschluss ist es sinnvoll den Zugriff zu testen und dann den SSH-Server so zu konfigurieren, dass eine Authentifizierung nur noch über Public-Key-Authentifizierung erlaubt ist. Daher setzen wir auf der Remote-Maschine die entsprechenden Zeilen in der /etc/sshd_config auf …
PasswordAuthentication no
… und starten den SSH-Service neu:
sytemctl restart sshd.service
Sofern man sich nun mit einem Passwort auf unserem SSH-Server anmelden möchte, erfolgt folgende Warnung und der Verbindungsaufbau wird abgebrochen:
<username>@<ziel>: Permission denied (publickey).
Perfekt: Damit kommt man nur noch via Public-Key-Authentifizierung auf unseren SSH-Server.
HinweisJe nach Betriebssystem oder eingesetzer Desktopumgebung unterscheidet sich die Handhabung des SSH-Agents. Die nachfolgenden Zeilen beschreiben die Verwendung auf einer Linux Shell (bash).
Die Verwendung der Public-Key-Authentifizierung erhöht die Sicherheit deutlich. Aber das Handling ist für uns noch etwas schwierig. Grund: Jeder Login erfordert eine Eingabe der oben gesetzten Passphrase.
Das kann auf dem Arbeitsgerät mit der Verwendung von ssh-agent optimiert werden. Den Agent starten wir mit folgendem Aufruf:
eval "$(ssh-agent -s)"
Nun können wir einen oder mehrere Keys in den ssh-agent laden. Das machen wir VOR einem Verbidnungsaufbau mit unseren SSH-Servern:
ssh-add ~/.ssh/id_ed25519_sshlab
Wir werden (1) nach der entsprechenden PASSPHRASE gefragt, die wir eingeben und erhalten im Anschluss die Meldung (2), dass der Key (die Identität) hinzugefügt wurde:

Wenn wir im späteren Verlauf kontrollieren wollen, welche Keys zum SSH-Agent hinzugefügt wurden, können wir das mit folgendem Befehl kontrollieren:
ssh-add -l
Das war es. Der Verbindungsaufbau erfolgt wie gehabt:
ssh -i ~/.ssh/id_ed25519_sshlab <username>@<ziel>
Im Gegensatz zum Verfahren ohne ssh-agent ist zu beobachten, dass wir nun die Passphrase bei Login nicht mehr übergeben mussten. Das übernimmt der ssh-agent ab jetzt und funktioniert so lange ich mich nicht aus der Sitzung am Arbeitsgerät abmelde. Will ich mich auf 10 Servern verbinden, muss ich meine Identität (meinen Key) nur einemal mit der PASSPHRASE an den ssh-agent übergeben und komme für den Rest der Zeit ohne Passwort auf meine Systeme. Auch Entwickler die ihre Projekte auf einer git-Instanz lagern und via SSH clonen, fetchen, pushen oder pullen, werden diesen Vorteil zu schätzen wissen.
Der Zugriff auf entfernte Systeme kann noch weiter vereinfacht werden. Hierzu wird die Client-Konfiguration auf dem Arbeitsgerät angepasst. Wie schon oben erwähnt, liegt die dazu notwendige Konfig-Datei unter /etc/ssh/ssh_config (diesmal ohne d) und ist global für alle Benutzerinnen und Benutzer eines Systems gültig.
Zudem gibt es im eigenen Verzeichnis unter ~/.ssh/config die Möglichkeit eine Konfigurationsdatei zu hinterlegen. Diese ist nur für den jeweiligen User gültig und der Ort der Wahl für unseren weiteren Anpassungen.
TippWindows-User erstellen die erwähnte Datei ebenfalls in ihrem Homeverzeichnis:
(z. B. unterC:\Users\<username>\.ssh\config)
In dieser Datei werden pro Host entsprechende Verbindungsparameter hinterlegt. Ein Beispiel für den Zugriff auf zwei verschiedene SSH-Server könnte wie folgt aussehen:
|
|
Der Verbindungsaufruf ist somit massiv verkürzt. Wollen wir uns mit dem SSH-Server vadersvm verbinden, erfolgt der Aufruf via:
ssh vadersvm
Es können auf diese Weise zahlreiche Zielhosts angegeben und einfach aufgerufen werden. Hier hat es sich übrigens für mich bewährt, dass ich pro Projekt eine eigene Config-Datei vorhalte. Dazu hab ich in meiner ~/.ssh/config die Anweisung Include config.d/* hinterlegt …
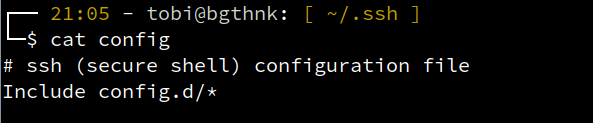
… und dann im angegebenen Ordner config.d die einzelnen Dateien abgespeichert:
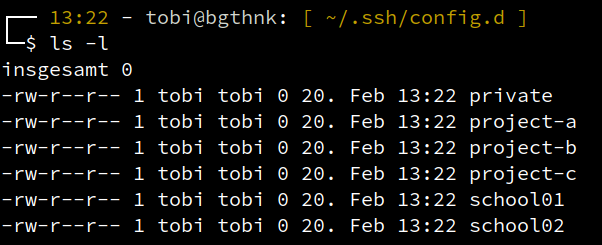
Der Vorteil von diesem Verfahren ist, dass ich dadurch etwas aufgeräumter arbeite und zudem die Dateien bei meinen jeweiligen Kollegen schnell austauschen kann.
Das ist jetzt ein relativ großer Beitrag geworden (für meine Verhältnisse). Und es wurden so viele Dinge noch nicht angesprochen, die einen weiteren Beitrag verlangen. Im Admin-Alltag nützlich sind z. B. die proxyjump-Verbindungsparamter und eigentlich gehört auch noch erwähnt, dass SSH-Agent-Forwarding eine kritische Funktion ist. Professionelle Umgebungen setzen zudem auf Zertifikate um ein Vertrauen zu einem SSH-Server herzustellen. Darüber hinaus gibt es noch weitere Möglichkeiten, wie man SSH in Arbeitsgruppen optimiert einsetzt.
Aber dieser Artikel sollte ein erster SSH-Grundlagen-Beitrag werden, der einen Überblick über das Protokoll, den sichern Zugriff auf Remote-Hosts und ein paar Tipps für das Handling zu Verfügung stellt. Ich hoffe dass ist mir halbwegs gelungen. Sofern ich hier zwischen den Zeilen irgend einen Quatsch fabriziert habe, freue ich mich über eine Rückmeldung auf den üblichen Kanälen.
Apropos Überblick: Eine schöne Übersicht, welche Dateien bei einer Public-Key-Authentifizierung relevant sind, findet man auf folgender Grafik:
