Wordle mit Regex lösen
Reguläre Ausdrücke (Regex oder RegExp) sind hilfreich, wenn relevante Informationen aus Texten heraus gefiltert werden müssen. In der Praxis ist das total hilfreich aber im Unterricht kann das Thema eine trockene Sache sein. Hier hilft es das Thema spielerisch anzugehen. Eine Idee ist das Lösen des Wortsuche-Spiels Wordle mit einer vorhandenen Wortliste und unter Verwendung von Regulären Ausdrücken.
Das originale Spiel ist auf den Seiten der New York Times . Allerdings gibt es hier nur ein Spiel pro Tag. Wer immer wieder neue Rätsel zum üben haben möchte, findet hier sein Glück:
Inhalt
Sinn des Spiels ist es eigentlich, das jeweilige Wort ohne Cheating zu finden. Allerdings ist die Intention hier im Blog-Beitrag, nicht das Spiel an sich, sondern Lernende an Regex zu gewöhnen. Daher ist das Ziel, das Spiel mit Hilfe von Regex und einer Wortliste sicher zu lösen.
Unter Debian gibt es das bereits installierte Paket wamerican. Falls ein deutschsprachiges Wordle gelöst werden soll, kann das ebenfalls schon vorhandene Paket wngerman verwendet werden. Die beiden Pakete stellen im Verzeichnis /usr/share/dict entweder eine englische (american-englisch) oder deutsche (ngerman) Wortliste bereit.
Zu Spielbeginn gibt man ein beliebigesi, fünfstelliges, Wort ein. Wenn keine oder wenige Treffer erzielt werden, verwendet man ein weiteres Wort, das möglichst keine Buchstaben aus dem ersten Versuch enthält. Im folgenden Beispiel kann das wie folgt aussehen.

Bei dem Versuch aus der Abbildung ist zu erkennen, dass die Buchstaben G und T an der korrekten Stelle stehen. Die Buchstaben I und L hingegen, sind zwar im Wort enthalten, aber stehen der falschen Stelle. Mit Regex kann jetzt gefiltert werden. Die englischsprachige Wortliste besteht aus 104.334 Wörtern:
cd /usr/share/dict/
wc -l american-english
In dem Spiel sind jedoch nur fünfstellige Wörter verlangt. Das heißt, zwischen Zeilenanfang ^ und Zeilenende $ müssen genau fünf Zeichen stehen (jeweils repräsentiert durch einen Punkt):
grep ^.....$ american-english
Es sind in der hier verwendeten Liste 7.044 fünfstellige Wörter enthalten. Das reduziert die verbleibende Anzahl der Lösungsmöglichkeiten erheblich, aber bringt hier noch keinen Mehrwert. Es verbleiben nur noch vier Versuche. Wenn im regulären Ausruck die Buchstaben G und T schon gesetzt werden, reduziert sich die Liste weiter. Zusätzlich wird über die Option -i die Unterscheidung zwischen Groß- und Kleinschreibung ignoriert:
grep -i ^..g.t$ american-english
Es verbleiben 24 Wörter. Das ist deutlich besser, aber immer noch schwer zu erraten. Es ist zu erkennen, dass die Buchstaben E, O, A, V, N und M überhaupt nicht enthalten sind. Also können diese an den noch nicht fest stehenden Stellen ausgeschlossen werden:
grep -i ^[^eoavnm][^eoavnm]g[^eoavnm]t$ american-english
Es verbleiben nur noch 8 Wörter. Weiterhin ist zus sehen, dass der Buchstabe I nicht an Stelle 4 sein kann. Der Filterausdruck wird somit entsprechend erweitert:
grep -i ^[^eoavnm][^eoavnm]g[^ieoavnm]t$ american-english
-> Es verbleiben 7 Wörter:
bight
fight
light
right
sight
tight
wight
Damit kann es weiter gehen. In der Folge wird ein weiteres Wort probiert:

Das Wort ist zwar nicht erraten, aber es ist zu sehen dass uns unser Vorgehen weiter bringt. Die Wortliste hat sich nicht weiter reduziert, was der angepasste reguläre Ausdruck verrät:
grep -i ^[^eoavnm]ight$ american-english
Die Liste hat die gleiche Länge wie zuvor:
bight
fight
light
right
sight
tight
wight
Es ist jedoch auch zu sehen, dass der Bustabe L enthalten sein muss. Das hätte auch schon im Schritt vorher auffallen können. Damit bleibt nur noch das letzte mögliche Wort Light:
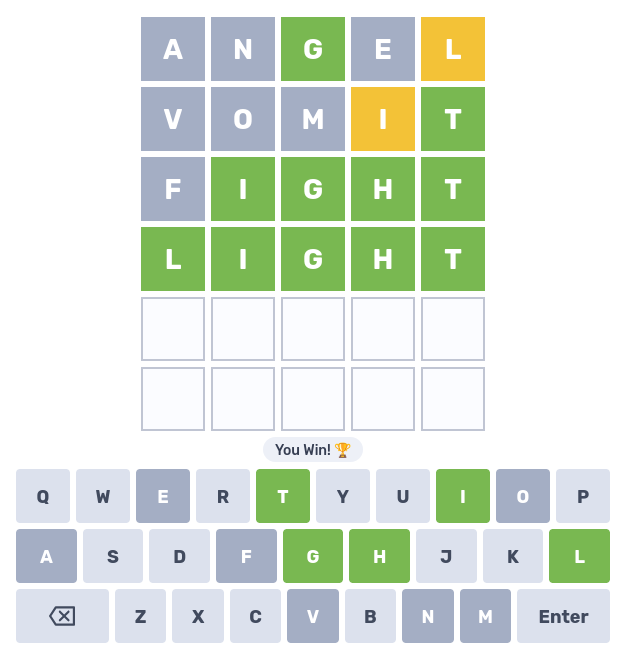
Die Ausgabe kann auch via Pipelines weiter gefiltert werden. Im nachfolgenden Beispiel wird nach den ersten beiden Eingabe-Versuchen im Spiel definiert, an welcher Stelle welcher Buchstabe nicht stehen kann und dann erneut gefilter, was als Buchstabe enthalten sein muss (egal an welcher Stelle). Damit wären wir schon nach drei Versuchen offensichtlich zum Ziel gekommen:
grep -i ^[^eoavnm][^eoavnm]g[^ieoavnm]t$ american-english | grep l
Viele Wege führen nach Rom: Die Verwendung oben ist nicht sehr elegant aber sie ist eine Art Herleitung wie man sich Schritt für Schritt zum Zielwort filtert. Mit folgender Eingabe kann man die Durchführung etwas effizienter durchführen:
grep -vi [eoavnm] american-english | grep -i ^..g.t$ | grep l
- Je nach verwendeter Wortliste verbleiben bei der Filterung mehr oder weniger Wörter als hier im Beispiel gezeigt.
- Es empfiehlt sich bei Wordle in den ersten beiden Versuchen möglichst alle Vokale auszuschließen
- In den Online verfügbaren Spielen können auch Wörter gesucht sein, die in den verwendeten Wortlisten nicht stehen. Dann kann das Spiel natürlich nicht auf die hier beschriebene Weise gelöst werden. Das ist aber eine sehr seltene Ausnahme.
Mit diesem Ansatz zur Lösung eines Spiels ist die Hürde zur Nutzung von Regulären Ausdrücken etwas weniger hoch und es wird schnell ersichtlich, dass mir das Werkzeug helfen kann. Darüber hinaus gibt es aber noch viele weitere Ideen. Witzig finde ich die Idee von @blinry , der auf seiner Webseite (vor vielen Jahren schon) einen kleinen Blogpost mit einem Hinweis hinterlegt hat, dass in den Kommentaren des Linux-Kernels zahlreiche Kraftausdrücke enthalten sind. Beispielhaftes vorgehen:
cd /tmp
wget https://cdn.kernel.org/pub/linux/kernel/v5.x/linux-5.19.12.tar.xz
tar -xJvf linux-5.19.12.tar.xz
cd linux-5.19.12
egrep -ir "(fuck|sucks|shit|bloody|crap)" .